夫子•明察司法大模型是由山东大学、浪潮云、中国政法大学联合研发,基于海量中文无监督司法语料(包括各类判决文书、法律法规等)与有监督司法微调数据(包括法律问答、类案检索)训练的中文司法大模型。该模型支持法条检索、案例分析、三段论推理判决以及司法对话等功能,旨在为用户提供全方位、高精准的法律咨询与解答服务。
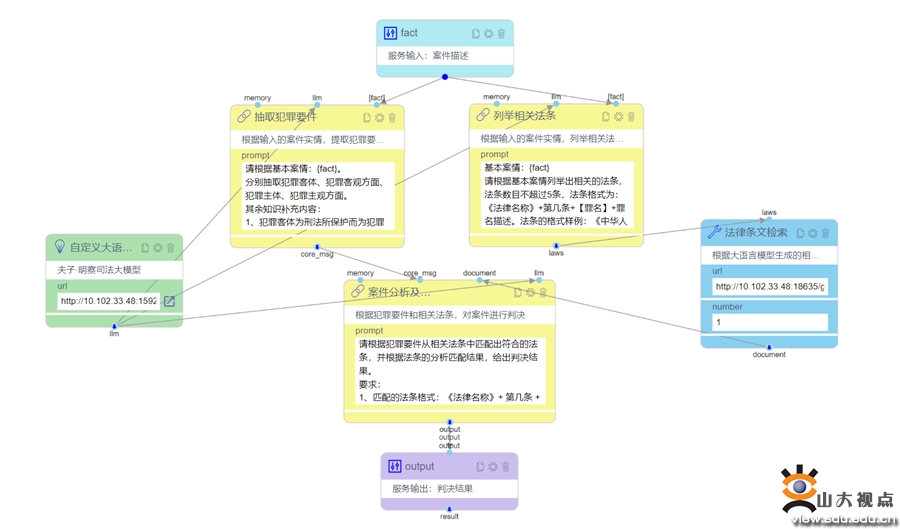
夫子•明察司法大模型具有三大特色:一、基于法条检索回复。夫子•明察大模型能够结合相关法条进行回复生成。对于用户的咨询,夫子•明察大模型基于生成式检索范式先初步引用相关法条,再检索外部知识库对所引法条进行校验与确认,最终结合这些法条进行问题分析与回复生成。这保证生成的回复能够基于与问题相关的法律依据,并根据这些依据提供深入的分析和建议,使回复具有高权威性、高可靠性与高可信性。二、基于案例检索回复。夫子•明察大模型能够基于历史相似案例对输入案情进行分析。大模型能够生成与用户提供的案情相似的案情描述及判决结果,通过检索外部数据库得到真实的历史案例,并将这些相似历史案例的信息用于辅助生成判决。生成的判决参考相关案例的法律依据,从而更加合理。用户可以对照相似案例,从而更好地理解潜在的法律风险。三、三段论推理判决。司法三段论,是把三段论的逻辑推理应用于司法实践的一种思维方式和方法。类比于三段论的结构特征,司法三段论就是法官在司法过程中将法律规范作为大前提,以案件事实为小前提,最终得出判决结果的一种推导方法。针对具体案件,夫子•明察大模型系统能够自动分析案情,识别关键的事实和法律法规,生成一个逻辑严谨的三段论式判决预测。这个功能不仅提供了对案件可能结果的有力洞察,还有助于帮助用户更好地理解案件的法律依据和潜在风险。
在数据组成方面,夫子•明察司法大模型的训练数据可分为两大类别:中文无监督司法语料以及有监督司法微调数据。其中不仅涵盖法律法规、司法解释、判决文书等内容,同时还包括各类高质量司法任务数据集,例如法律问答、类案检索和三段论式法律判决。内容丰富、优质海量的训练数据,确保了对司法领域知识进行准确且全面的覆盖,为夫子•明察司法大模型提供坚实的知识基础。
夫子•明察大模型的训练过程分为两个关键阶段:大规模司法语料的增量预训练和基于高质量司法数据的模型微调。第一阶段,使用大规模司法语料,对chatglm基座大模型进行增量预训练。针对司法领域,使用约2000万条判决文书和法律法规等司法语料(共约400亿token),对夫子•明察大模型进一步增量预训练,使模型获得在法律领域的基础理解能力。第二阶段,利用有标注司法数据,对夫子•明察大模型进行微调。针对司法领域,使用近20万条高质量司法任务数据来增强模型领域指令遵循的能力。为了防止模型遗忘通用指令遵循能力,微调数据中引入通用领域指令微调数据。通过全量微调,夫子•明察大模型在下游法律任务上的表现显著提升。
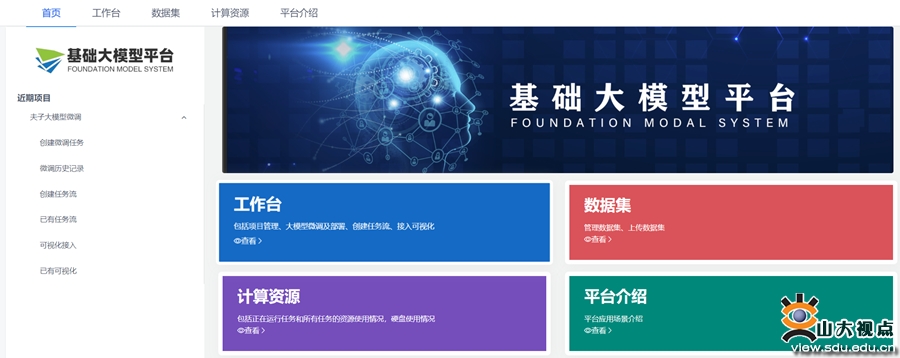
夫子•明察司法大模型是基于山东大学数链融合技术教育部工程研究中心自主研发的基础大模型平台—aizoo训练而成。aizoo是一个开放、自主、可控的多学科融合人工智能支撑平台,包含可视化、机器学习、深度学习、自然语言处理模块、图像处理模块等前沿技术,可用于实验设计,模型设计和指标测评等科研活动,实现产、学、研、用一体化发展。


 微信公众号
微信公众号
